
The widespread development of artificial intelligence, and in particular the launch of Cat By Openai with its incredibly precise and logical responses and dialogues, aroused public conscience and raised a new wave of interest in models of great language (LLM). It has certainly become clear that their possibilities are larger than we have never imagined. The titles reflected both excitement and concern: can robots write a cover letter? Can they help students take tests? Will bots influence voters via social media? Are they able to create new designs instead of artists? Will they put writers without work?
After the spectacular release of Chatgpt, there are now discussions on similar models on Google, Meta and other companies. Computer scientists call for a more in -depth examination. They believe that the company needs a new level of infrastructure and tools to protect these models and focuses on the development of these infrastructures.
One of these key guarantees could be a tool that can provide teachers, journalists and citizens the ability to distinguish between the texts generated by the LLM and the texts written by man.
To this end, Eric Anthony Mitchell, student graduated in the fourth year in computer science at the University of Stanford, while working on his doctorate with his colleagues developed Detect. It was published in the form of a demo and document which distinguishes the text generated by LLM from the text written by man. In initial experiences, the tool precisely determines 95% of the time in five popular open source llms. The tool is at its beginnings of development, but Mitchell and his colleagues work to ensure that he will be very advantageous for society in the future.
Certain general approaches to resolve the problem of identifying the paternity of texts have already been sought. An approach, used by Openai itself, consists in forming the model with texts of two types: certain texts generated by LLM and others created by humans. The model is then invited to identify the authorship of the text. But, according to Mitchell, so that this solution succeeds in subjects and in different languages, this method would require a huge amount of training data.
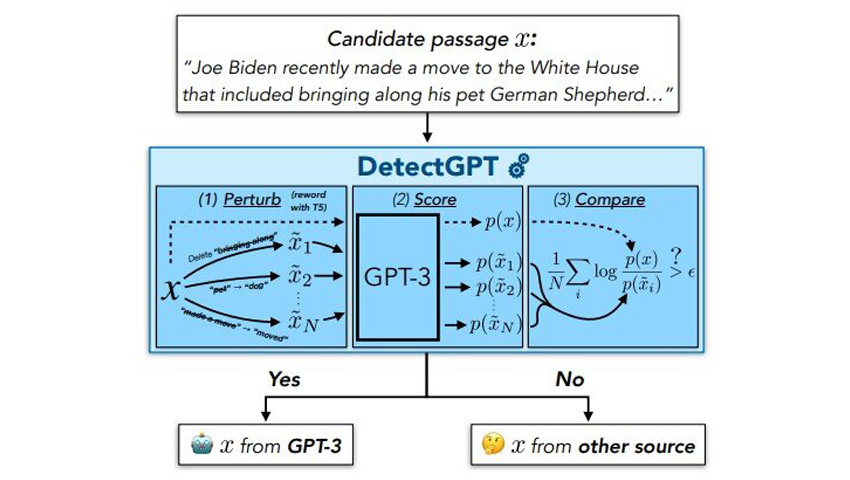
The second approach avoids forming a new model and simply uses LLM to discover its own outing after fueling the text in the model.
Essentially, the technique is to ask the LLM how much it “likes” the text sample, explains Mitchell. And by “like”, he does not mean that it is a sensitive model that has its own preferences. On the contrary, if the model “likes” a text, it can be considered as a high note of the model for this text. Mitchell suggests that if a model likes a text, it is likely that the text has been generated by it or similar models. If he doesn't like the text, then it was probably not created by LLM. According to Mitchell, this approach works much better than random supposition.
Mitchell suggested that even the most powerful LLMs have a certain bias against the use of a phrasing of one idea compared to another. The model will be less inclined to “like” a slight paraphrase of its own outing than the original. At the same time, if you deform the human manual text, the probability that the model loves it more or less that the original is almost the same.
Mitchell also realized that this theory could be tested with popular open source models, including those available via the Openai API. After all, the calculation of the model likes a particular text is essentially the key to teaching the model. It can be very useful.
To test their hypothesis, Mitchell and his colleagues have conducted experiences in which they observed how LLM accessible to the public loved the text created by man as well as their own text generated by LLM. The selection of texts included false press articles, creative writing and academic essays. The researchers also measured the quantity of LLM loved, on average, 100 distortions of each LLM and the written text on man. After all the measures, the team has drawn the difference between these two numbers: for LLM texts and for the texts written by man. They saw two bells of bells that barely overlapped. The researchers have concluded that it is possible to distinguish the source from texts very well using this single value. In this way, a much more reliable result can be obtained in relation to the methods which simply determine how the model likes the original text.
In the initial experiences of the team, Detectgpt succeeded in identifying the human written text and the text generated by LLM 95% of the time when using GPT3-NEOX, a powerful open source variant of OPENAI GPT models. Detectgpt was also able to detect text created by man and text generated by LLM using LLM other than the original source model, but with slightly lower precision. At the time of initial experiences, the chatgpt was not yet available for direct tests.
Other companies and teams are also looking for ways to identify the text written by AI. For example, Openai has already published its new text classifier. However, Mitchell does not want to directly compare OpenAi's results with those of Detectgpt, as there is no standardized dataset to assess. But his team had some experiments using the previous generation of the pre-formulated IA detector of Openai and found that he had performed well with English articles in English, performed with medical articles and completely failed with press articles in German. According to Mitchell, these mixed results are typical for models that depend on pre-training. On the other hand, Detectgpt worked satisfactorily for the three text categories.
DETECTGPT user comments have already helped to identify certain vulnerabilities. For example, a person can specifically request chatgpt to avoid detection, such as specifically asking LLM to write text as a human. The Mitchell team already has some ideas on how to mitigate this drawback, but they have not yet been tested.
Another problem is that students using LLMs, such as Chatgpt, to cheat on homework, simply modify the text generated by AI to avoid detection. Mitchell and his team studied this possibility in their work and found that if the quality of detection of the edited trials decreased, the system still does a fairly good work of identifying the text generated by the machine when less than 10 to 15% of the words have been modified.
In the long term, the objective of the detectgpt is to provide the public with a reliable and effective tool to predict whether the text, or even a part of it, was generated by the machine. Even if the model does not think that the whole test or the press article has been written by the machine, there is a need for a tool which can highlight a paragraph or a sentence which seems particularly generated by the machine.
It should be noted that, according to Mitchell, there are many legitimate uses for an LLM in education, journalism and other areas. However, providing the public with tools to verify the source of information has always been beneficial and even remains in the AI era.
Detectgpt is only one of the many works that Mitchell creates for LLM. Last year, he also published several approaches to LLM publishing, as well as a strategy called “self-destruction models” which deactivates LLM when someone tries to use it for harmful purposes.
Mitchell hopes to refine each of these strategies at least once again before finishing their doctorate.
The study is published on the arxiv Pre -print of the server.