Amazon's last breakthrough in artificial intelligence (AI) has shook the world of technology with the unveiling of The largest vocal text model. Developed by a team of AI researchers at Amazon AG, this colossal model has 980 million impressive parameters and was formed using 100,000 hours of recorded speeches, mainly in English. Named the Big adaptive streammable TTS with emerging capacities (Base TTS), this innovative model represents a significant leap in the field of speech synthesis technology.
Decompos its most captivating features:
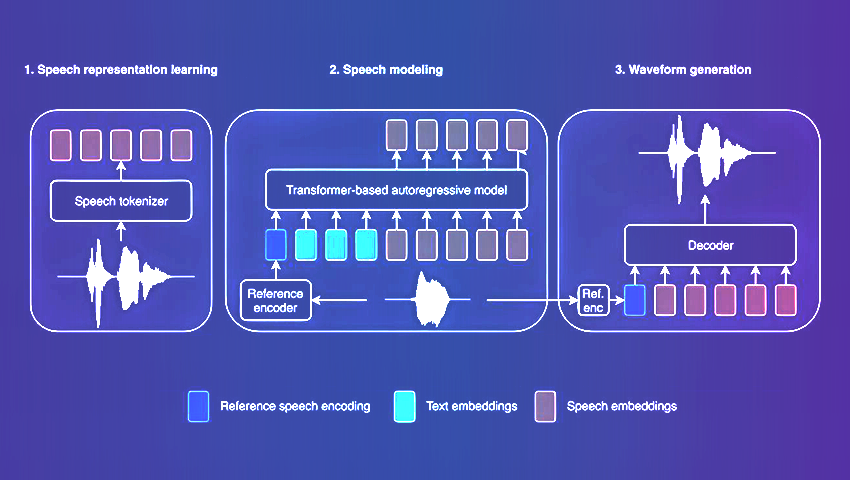
Architecture
- Self -regressive transformer of $ 1 billion billion: at its heart, the TTS base has a massive self -regressive transformer. This neural network converts the raw text into discreet codes called “vocal codes”.
- Decoder based on the convolution: according to the codes of speech, a decoder based on a convolution transforms them into real wave shapes. Beauty lies in its increasing and diffusable approach, allowing real -time synthesis.
A new approach to speech codes
- Vocal tokens based on Autoencoder: Base TTS presents a new technique of speech tokenization. These speech tokens dissociate the identity of the loudspeaker and compress information using the coding of bytes pairs.
- Detaining the speaker's ID: Imagine a TTS system that can imitate different speakers transparently. The TTS base succeeds by unraveling the characteristics of the raw audio speakers.
- Emergence of natural prosody: echoing the phenomenon observed in large -language models, basic TTS variants with 10k + hours and 500 m + parameters begin to present a natural prosody even on complex sentences.
Peak natural
- Naturality of speech: The base TTS establishes a new reference for the natural. Its outing competes with large -scale TTS systems accessible to the public such as the TTS of YOURTTS, BARK and TORMOISE.
- Complex words, emotions and punctuation: The base TTS manages the complex vocabulary, infuses emotions and punctuation nails. It's not just robotic; It's expressive.
Peak natural
- Data efficiency: The TTS database shows that data efficiency can be integrated into large -scale models. He obtained remarkable results with fewer hours of training.
- Streamability: the incremental and diffusable approach opens doors for real -time applications in voice assistants, audio books, etc.
The importance of the base TTS lies not only in the pure scale of the model but also in its emerging capacities – a phenomenon where the application of AI has a sudden breakthrough of intelligence. Thanks to rigorous tests, the researchers discovered that this jump occurred at the 150 million parameters, highlighting the critical role of the size of the data set in the conduct of progress in AI capacities.
One of the most remarkable characteristics of the basic TTS model is its versatility in the management of various language attributes. From compound names complex to emotional expressions, pronunciations of foreign language and even nuances in intonation and punctuation, the model demonstrates an impressive command on linguistic subtleties. In addition, its ability to correctly emphasize keywords in a sentence and to ask questions with precision adds another layer of sophistication to its functionality.
Although the basic TTS model is not made public due to ethical concerns surrounding its potential abusive use, the Amazon's research team plans to take advantage of its learning to improve the overall quality of vocal text applications.
However, you may feel the convenience of Online vocal text service of Qudata right away! Take advantage of our technology of synthesis of freedom of expression and convert the written text into an effortless voice.